浅谈python数据类型及其操作
一、Number 数字

1.内置函数:需要导入math
2.随机数函数:需要导入random 模块
3.三角函数:需要导入math模块
4.数学常量:需要导入math模块
#1.数据函数的使用 #========================== #内置函数 print(abs(-10))#10绝对值 print(round(4.56789,2)) #4.57 使用四舍五入的方式保留小数点后两位 a = [10,30,20,80,50] print(max(a))#80 最大值 print(min(a))#10 最小值 #需要导入math import math print(math.ceil(2.3))#3 进一取整 print(math.floor(2.99999)) #2 舍去取整
10
4.57
80
10
3
#2.随机数函数 #============================= #需要导入random 模块 import random print(random.random()) #随机一个0~1的小数 print(random.choice(['aaa','bbb','cccc']))#随机获取一个值 #指定范围的随机 print(random.randrange(10)) #随机0~9的一个值 print(random.randrange(4,10)) #随机4~9的一个值 print(random.randrange(0,10,2)) #随机4~9的一个值 b = [1,2,3,4,5,6] random.shuffle(b) #将容器内的值顺序打乱 print(b)
0.6045140519996484
cccc
3
4
0
[1, 3, 4, 6, 5, 2]
#3.三角函数 #需要导入math模块 print(math.sin(90)) print(math.cos(0))
0.8939966636005579
1.0
#4.数学常量 #需要导入math模块 print(math.pi) #圆周率 print(math.e) #自然常数
3.141592653589793
2.718281828459045
二、String 字符串

# 1.字符流(str 字符串) <=> 字节流(bytes 字符串、二进制)之间的转换 #字符流转换为字节流 str = "zhangsan" b1 = str.encode(encoding="utf-8") print(b1) b2 = bytes(str,encoding="utf+8") #结果中,只要是b开头的都叫字节流 print(b2) #字节流转成字符流 print(b1.decode(encoding="utf-8")) #由字节转成字符 print(bytes.decode(b2,encoding="utf-8"))
b'zhangsan'
b'zhangsan'
zhangsan
zhangsan
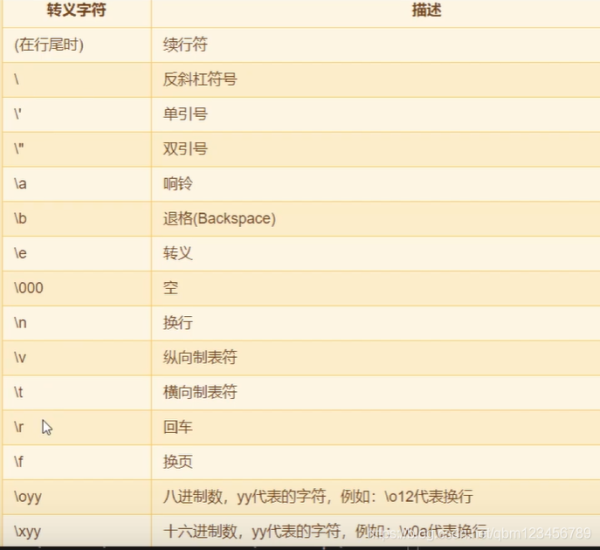
#2.转义符的使用
print("ab\\cde\n\rfg\thijk\"lmnopq")
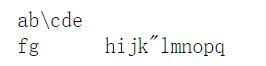
#3. 字符串的格式化:format %
print("a={};b={}".format(10,20)) #用括号作占位符。
print("a={1};b={0}".format(10,20)) # 指定索引号代表第几参数
print("a={0};b={0}".format(10))
print("name={name:10};age={age}".format(age=20,name="lisi"))#name:10 表示占10个宽度。
print("name={name:<10};age={age}".format(age=20,name="lisi"))#小于号:靠左边;大于号:靠右边。
print("{:.2f}".format(5.6789))# .2f表示保留小数后两位
name="zhangsan"
print(f"name={name}")
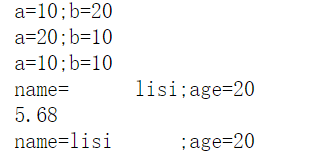
#4.字符串的内建函数
#==============================
name = "ZhangSan"
print(name,name.upper(),name.lower()) #字符串的大小写
print("字符串长度:",len(name))
print("统计字符串中an出现的次数:",name.count('an'))
print("字符串替换: ",name.replace("San","wuji"))
print("10:20:30:40".split(":")) #字符串拆分(列表)

# 字符串查找
str = "zhangsanfang"
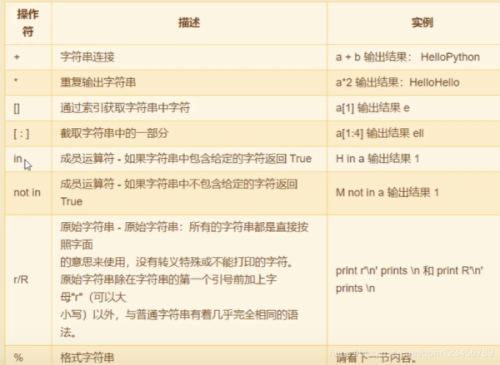
print(str.find("an"))#从头开始查找 ,找不到返回-1
print(str.rfind("an"))#从末尾开始查找 ,找不到返回-1
print(str.index("an")) #从头查找,找不到报错
print(" aaa ".strip())#去除字符串两侧多余空格(或指定字符)
print(" aaa ".lstrip())#去除字符串左侧多余空格(或指定字符)
print(" aaa ".rstrip())#去除字符串右侧多余空格(或指定字符)



三、List 列表

# 1. 列表的定义 list1 = [] #定义一个空列表 list2 = list() #定义一个空列表 list3 = ['python','java','php',10,20] #定义列表 list4 = [1,2,3,4,5,6,7] #定义列表 print(list4) list4[3] = 400 #修改 print(list4) del list4[5]#删除 print(list4)
[1, 2, 3, 4, 5, 6, 7]
[1, 2, 3, 400, 5, 6, 7]
[1, 2, 3, 400, 5, 7]
10 20 30 40 50
10 20 30 40 50
# 2.列表的遍历 a = [10,20,30,40,50] #使用for ... in 遍历 for i in a: print(i,end= " ") print() #使用while循环遍历 i = 0 while i <len(a): print(a[i],end= " ") i += 1 print()
10 20 30 40 50
10 20 30 40 50
#遍历等长的二阶列表 b = [["aa","AAA"],["bb","BBB"],["cc","CCC"]] for v1,v2 in b: print(v1,v2) #遍历不规则二阶列表 c = [[10,20],[30,40,50],[60,70],[80,90,100,110,120]] for v in c: for i in v: print(i,end=" ") print()

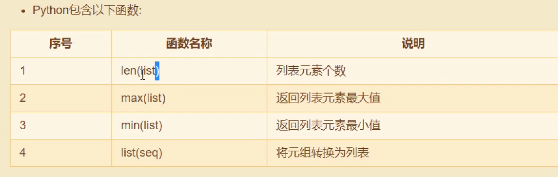
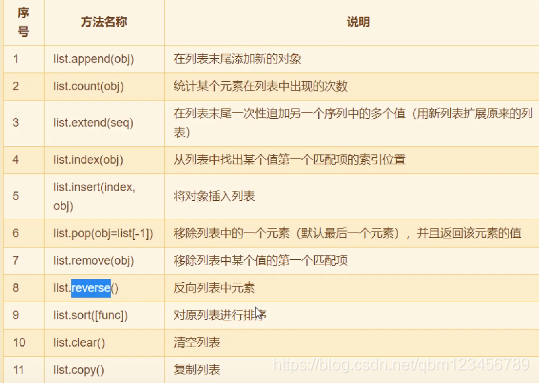
# 4. 列表的方法 (非常重要)
a = ['zhangsan','lisi']
a.append('wangwu') #在列表的尾部新增值
a.extend(['zhaoliu','xiaolin'])#在列表尾部添加多个值
a.insert(3,"qqq") #在指定位置插入一个值
print(a)
b = [1,2,3,3,2,1,4,5]
print(b.count(1)) #统计1在列表中出现的次数
print(b.index(5)) #5出现的位置
print(a.pop()) #最后一个值
a.remove("zhangsan") #删除指定值
print(a)
a.reverse() #颠倒顺序
print(a)
b.sort()#升序
print(b)
b.clear() #清空
print(b)

a = [10,20,30] b = a c = a.copy()#浅复制:复制一个列表 print(id(a),id(b),id(c)) a[1] = 200 print(a) print(b) print(c)
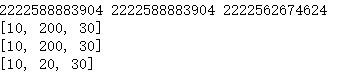
四、Tuple 元组

#========================================
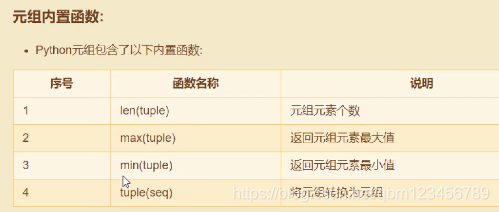
#1. 定义元组的方式
tup0 = () #定义一个空元组 或者变量 = tuple() (没有意义,因为元组不能被修改)
tup1 = ('Google','Python',1997,2000)
tup2 = (1,2,3,4,5)
tup3 = "a","b","c","d"
#输出元组:
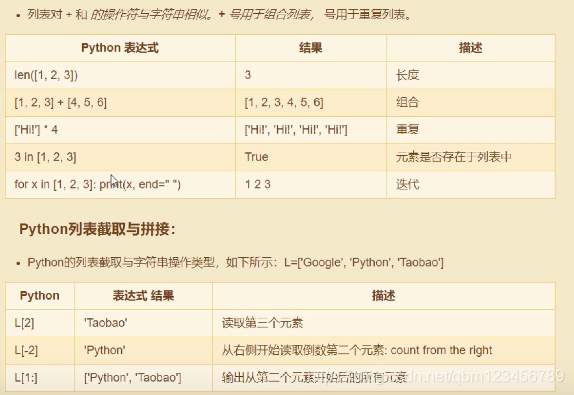
print("tup1[0]: ",tup1[0])
print("tup2[1:5]:",tup2[1:5])
#注意下面这种定义下不加逗号,类型为整型
tup4 = (50)
print(type(tup4))
#以下修改元组元素操作是非法的。
#tup1[0] = 100
#元组中的元素值是不允许删除的,但可使用del语句来删除整个元组
del tup0;
tup1[0]: Google
tup2[1:5]: (2, 3, 4, 5)
<class ‘int'>
#2. 元组的遍历 #=========================== a = (10,20,30,40,50) #使用for ... in 遍历 for i in a: print(i) # 使用while遍历 i = 0 while i<len(a): print(a[i]) i += 1
10
20
30
40
50
10
20
30
40
50
10 20
30 40
50 60
#遍历等长二级元组 b = ((10,20),(30,40),(50,60)) for v1,v2 in b: print(v1,v2) #遍历不等长二级元组 b = ((10,20),(30,40,50,60),(70,80,90)) for v in b: for i in v: print(i,end=" ") print()
10 20
30 40
50 60
10 20
30 40 50 60
70 80 90
# 4. 元组的操作符: #==================================== a = (1,2,3) b = (4,5,6,7) print(len(a)) print(a+b) print(a*2) print(6 in b) #判断一个值是否在一个元组中 #获取 print(b[2]) print(b[-2]) print(b[1:]) print(b[1:3])
3
(1, 2, 3, 4, 5, 6, 7)
(1, 2, 3, 1, 2, 3)
True
6
6
(5, 6, 7)
(5, 6)

五、Sets集合

# 1.集合的基础操作
#====================================
#定义集合的方式:
#集合的定义
set1 = set() #定义一个空的集合
set2 = {1,2,3}
#增加一个元素
set1.add(5)
#增加多个:参数可以是列表或元组
set1.update([5,6,7,8])
#删除某个值(参数为元素值,没有会报错)
set2.remove(1)
set2.discard(50) #删除不存在的值不会报错
#查:无法通过下标索引
#改:不可变类型无法修改元素
#清空集合
set2.clear()
a = {10,20,30}
b = {20,50}
print(a - b) #a和b的差集
print(a | b) #a和b的并集
print(a & b) #a和b的交集
print(a ^ b) #a和b中不同时存在的元素
# 2. 集合的遍历
#======================================
a = {10,20,30,40,50}
#使用for ... in 遍历
for i in a:
print(i)
#注:没有while遍历,因为没有排序,
#遍历等长二级集合
b = {(10,20),{30,40},(50,60)}
for v1,v2 in b:
print(v1,v2)

# 4. 集合的操作符
a = {1,2,3}
print(len(a)) #3 集合长度
print(6 in a) #判断一个值是否在一个集合中
3
False

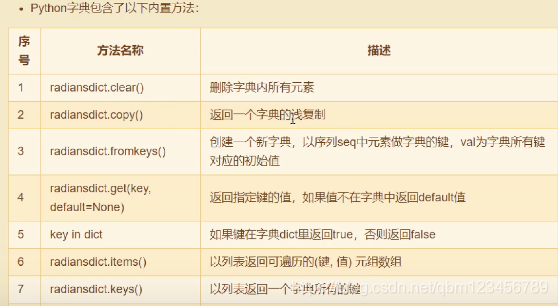
六、Dictionary 字典 (非常重要)

#字典是另一种可变容器模型,且可存储任意类型对象
# 1. 字典的基础操作:
#==============================
#定义字典的方式:
#字典的定义
d0 = {} #或dict()#定义一个空的字典
d1 = {'name':'python','age':17,'class':'first'}
#输出子字典中的信息
print("d1['name']: ",d1['name']) #python
print("d1['age']: ",d1['age']) #17
#输出错误信息:KeyError
# print("d1['alice']:",d1['alice'])
#修改和添加内容
d1['age'] = 18; #key存在则更新age
d1['school'] = '云课堂'# 不存在则添加信息
print(d1)
#删除信息
del d1['name']#删除键'name'一个元素值
d1.clear() #清空字典
del d1

#2. 字典的遍历
#===================================
d1 = {'name':'python','age':17,'class':'first'}
#使用for...in 遍历(默认遍历键)
for k in d1:
print(k,"=>",d1[k])
#遍历键和值(使用items())
for k,v in d1.items():
print(k,"===>",v)

# 3. 推倒式的使用 #================================ a = [1,2,3,4,5,6,7,8] #遍历列表a中的值i ,并判断是否是偶数,并形成新的列表保留下来 b = [i for i in a if i%2==0]#for i in a ,循环a列表,拿这个列表的值; if i%2==0 这个值若能被2整除,拿出来; 前面的i表示新生成一个列表 print(b)
[2, 4, 6, 8]
stu = {'name':'zhangsan','age':20,'sex':'man'}
#将当前stu字典遍历形成一个新的字典,去掉了age
s1 = {k:v for k,v in stu.items()}#for k ,v in stu.items()遍历字典;k:v形成新的字典;if k != "age" 作判断
s2 = {k:v for k,v in stu.items() if k !="age"}#for k ,v in stu.items()遍历字典;k:v形成新的字典;if k != "age" 作判断
print(s1)
print(s2)
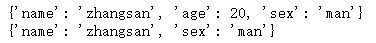
# 字典的操作方法
#=================================
stu = {'name':'zhangsan','age':20,'sex':'man'}
print(stu.items()) #以列表方式返回当前字典的键值对
print(stu.keys())
print(stu.values())
print(stu.get("name")) #
print(stu.get("iphone",None)) #获取指定key的值,若无返回None
print(stu.pop('age'))#弹出指定key的值,表示字典中没有了此内容
print(stu)
print(stu.popitem()) #随机弹出一对信息(移除了),默认最后一个。
print(stu)
stu.clear()

#容器的拷贝(浅拷贝和深度拷贝)
#浅拷贝
a = {"name":"zhanngsan","data":[10,20,30]}
b = a.copy()#浅拷贝
a["name"] = 'lisi'
a["data"][1] = 200
print(a)
print(b)

#导入一个深度拷贝模块
import copy
a = {"name":"zhanngsan","data":[10,20,30]}
b = copy.deepcopy(a)#深度拷贝
a["name"] = 'lisi'
a["data"][1] = 200
print(a)
print(b)
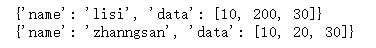
到此这篇关于浅谈python数据类型及其操作的文章就介绍到这了,更多相关python数据类型内容请搜索本站以前的文章或继续浏览下面的相关文章希望大家以后多多支持本站!
版权声明:本站文章来源标注为YINGSOO的内容版权均为本站所有,欢迎引用、转载,请保持原文完整并注明来源及原文链接。禁止复制或仿造本网站,禁止在非www.yingsoo.com所属的服务器上建立镜像,否则将依法追究法律责任。本站部分内容来源于网友推荐、互联网收集整理而来,仅供学习参考,不代表本站立场,如有内容涉嫌侵权,请联系alex-e#qq.com处理。
 关注官方微信
关注官方微信