python 爬取影视网站下载链接
发布日期:2022-04-01 19:26 | 文章来源:源码之家
项目地址:
https://github.com/GriffinLewis2001/Python_movie_links_scraper
运行效果
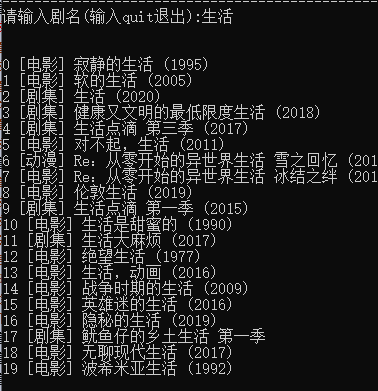
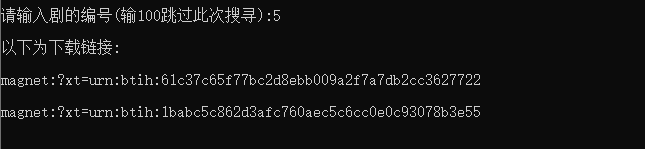
导入模块
import requests,re from requests.cookies import RequestsCookieJar from fake_useragent import UserAgent import os,pickle,threading,time import concurrent.futures from goto import with_goto
爬虫主代码
def get_content_url_name(url):
send_headers = {
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}
cookie_jar = RequestsCookieJar()
cookie_jar.set("mttp", "9740fe449238", domain="www.yikedy.co")
response=requests.get(url,send_headers,cookies=cookie_jar)
response.encoding='utf-8'
content=response.text
reg=re.compile(r'<a href="(.*?)" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="thumbnail-img" title="(.*?)"')
url_name_list=reg.findall(content)
return url_name_list
def get_content(url):
send_headers = {
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}
cookie_jar = RequestsCookieJar()
cookie_jar.set("mttp", "9740fe449238", domain="www.yikedy.co")
response=requests.get(url,send_headers,cookies=cookie_jar)
response.encoding='utf-8'
return response.text
def search_durl(url):
content=get_content(url)
reg=re.compile(r"{'\\x64\\x65\\x63\\x72\\x69\\x70\\x74\\x50\\x61\\x72\\x61\\x6d':'(.*?)'}")
index=reg.findall(content)[0]
download_url=url[:-5]+r'/downloadList?decriptParam='+index
content=get_content(download_url)
reg1=re.compile(r'title=".*?" href="(.*?)" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ')
download_list=reg1.findall(content)
return download_list
def get_page(url):
send_headers = {
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}
cookie_jar = RequestsCookieJar()
cookie_jar.set("mttp", "9740fe449238", domain="www.yikedy.co")
response=requests.get(url,send_headers,cookies=cookie_jar)
response.encoding='utf-8'
content=response.text
reg=re.compile(r'<a target="_blank" class="title" href="(.*?)" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" title="(.*?)">(.*?)<\/a>')
url_name_list=reg.findall(content)
return url_name_list
@with_goto
def main():
print("=========================================================")
name=input("请输入剧名(输入quit退出):")
if name == "quit":
exit()
url="http://www.yikedy.co/search?query="+name
dlist=get_page(url)
print("\n")
if(dlist):
num=0
count=0
for i in dlist:
if (name in i[1]) :
print(f"{num} {i[1]}")
num+=1
elif num==0 and count==len(dlist)-1:
goto .end
count+=1
dest=int(input("\n\n请输入剧的编号(输100跳过此次搜寻):"))
if dest == 100:
goto .end
x=0
print("\n以下为下载链接:\n")
for i in dlist:
if (name in i[1]):
if(x==dest):
for durl in search_durl(i[0]):print(f"{durl}\n")
print("\n")
break
x+=1
else:
label .end
print("没找到或不想看\n")
完整代码
import requests,re
from requests.cookies import RequestsCookieJar
from fake_useragent import UserAgent
import os,pickle,threading,time
import concurrent.futures
from goto import with_goto
def get_content_url_name(url):
send_headers = {
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}
cookie_jar = RequestsCookieJar()
cookie_jar.set("mttp", "9740fe449238", domain="www.yikedy.co")
response=requests.get(url,send_headers,cookies=cookie_jar)
response.encoding='utf-8'
content=response.text
reg=re.compile(r'<a href="(.*?)" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="thumbnail-img" title="(.*?)"')
url_name_list=reg.findall(content)
return url_name_list
def get_content(url):
send_headers = {
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}
cookie_jar = RequestsCookieJar()
cookie_jar.set("mttp", "9740fe449238", domain="www.yikedy.co")
response=requests.get(url,send_headers,cookies=cookie_jar)
response.encoding='utf-8'
return response.text
def search_durl(url):
content=get_content(url)
reg=re.compile(r"{'\\x64\\x65\\x63\\x72\\x69\\x70\\x74\\x50\\x61\\x72\\x61\\x6d':'(.*?)'}")
index=reg.findall(content)[0]
download_url=url[:-5]+r'/downloadList?decriptParam='+index
content=get_content(download_url)
reg1=re.compile(r'title=".*?" href="(.*?)" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ')
download_list=reg1.findall(content)
return download_list
def get_page(url):
send_headers = {
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}
cookie_jar = RequestsCookieJar()
cookie_jar.set("mttp", "9740fe449238", domain="www.yikedy.co")
response=requests.get(url,send_headers,cookies=cookie_jar)
response.encoding='utf-8'
content=response.text
reg=re.compile(r'<a target="_blank" class="title" href="(.*?)" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" title="(.*?)">(.*?)<\/a>')
url_name_list=reg.findall(content)
return url_name_list
@with_goto
def main():
print("=========================================================")
name=input("请输入剧名(输入quit退出):")
if name == "quit":
exit()
url="http://www.yikedy.co/search?query="+name
dlist=get_page(url)
print("\n")
if(dlist):
num=0
count=0
for i in dlist:
if (name in i[1]) :
print(f"{num} {i[1]}")
num+=1
elif num==0 and count==len(dlist)-1:
goto .end
count+=1
dest=int(input("\n\n请输入剧的编号(输100跳过此次搜寻):"))
if dest == 100:
goto .end
x=0
print("\n以下为下载链接:\n")
for i in dlist:
if (name in i[1]):
if(x==dest):
for durl in search_durl(i[0]):print(f"{durl}\n")
print("\n")
break
x+=1
else:
label .end
print("没找到或不想看\n")
print("本软件由CLY.所有\n\n")
while(True):
main()
以上就是python 爬取影视网站下载链接的详细内容,更多关于python 爬取下载链接的资料请关注本站其它相关文章!
版权声明:本站文章来源标注为YINGSOO的内容版权均为本站所有,欢迎引用、转载,请保持原文完整并注明来源及原文链接。禁止复制或仿造本网站,禁止在非www.yingsoo.com所属的服务器上建立镜像,否则将依法追究法律责任。本站部分内容来源于网友推荐、互联网收集整理而来,仅供学习参考,不代表本站立场,如有内容涉嫌侵权,请联系alex-e#qq.com处理。
相关文章
下一篇:
 关注官方微信
关注官方微信