写一个Python脚本下载哔哩哔哩舞蹈区的所有视频
一、抓取列表
首先点开舞蹈区先选择宅舞列表。
然后打开 F12 的控制面板,可以找到一条 https://api.bilibili.com/x/web-interface/newlist?rid=20&type=0&pn=1&ps=20&jsonp=jsonp&callback=jsonCallback_bili_57905715749828263 的 url,其中 rid 是 B 站的小分类,pn 是页数。
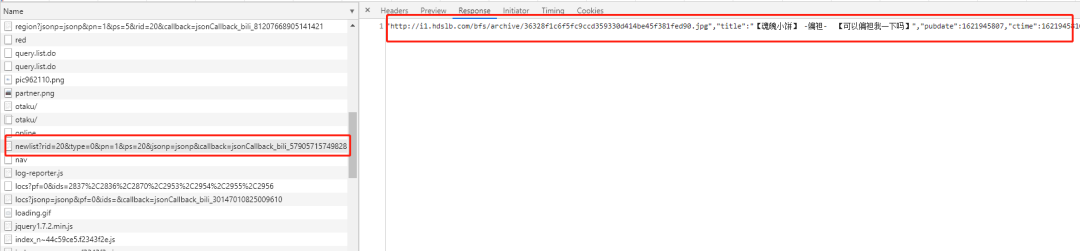
小编试着在浏览器将地址打开居然报了 404,可是在控制面板中这个地址的返回值明明就是视频列表。试着去掉 callback 的参数,意外的得到了想要的结果。

众所周知 bid 是一个 B 站视频的唯一 ID,想要获取 bid 可以从上面 url 的返回值中提取 aid,然后将 aid 转换为 bid。
Str='fZodR9XQDSUm21yCkr6zBqiveYah8bt4xsWpHnJE7jL5VG3guMTKNPAwcF'#准备的一串指定字符串
Dict={}
#将字符串的每一个字符放入字典一一对应,如 f对应0 Z对应1 一次类推。
foriinrange(58):
Dict[Str[i]]=i
s=[11,10,3,8,4,6,2,9,5,7]#必要的解密列表
xor=177451812
add=100618342136696320#这串数字最后要被减去或加上
defalgorithm_enc(av):
ret=av
av=int(av)
av=(av^xor)+add
#将BV号的格式(BV+10个字符)转化成列表方便后面的操作
r=list('BV')
foriinrange(10):
r[s[i]]=Str[av//58**i%58]
return''.join(r)
deffind_bid(p):
bids=[]
r=requests.get(
'https://api.bilibili.com/x/web-interface/newlist?&rid=20&type=0&pn={}&ps=50&jsonp=jsonp'.format(p))
data=json.loads(r.text)
archives=data['data']['archives']
foriteminarchives:
aid=item['aid']
bid=algorithm_enc(aid)
bids.append(bid)
returnbids
二、获取视频的 CID
想要下载 1080 的视频,光有 bid 是不够的,还需要 登录后 Cookie 中的 SESSDATA 值和 cid 。
首先登录 B 站将 Cookie 中的 SESSDATA 复制到对象头中。用地址为 https://api.bilibili.com/x/player/pagelist?bvid= url 返回 cid。
defget_cid(bid):
url='https://api.bilibili.com/x/player/pagelist?bvid='+bid
headers={
'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/90.0.4430.212Safari/537.36',
'Cookie':'SESSDATA=182cd036%2C1636985829%2C3b393%2A51',
'Host':'api.bilibili.com'
}
html=requests.get(url,headers=headers).json()
infos=[]
data=html['data']
cid_list=data
foritemincid_list:
cid=item['cid']
title=item['part']
infos.append({'bid':bid,'cid':cid,'title':title})
returninfos
三、下载视频
下载视频的 https://api.bilibili.com/x/player/playurl 来自于每次视频播放完之后的推荐列表。

最后使用 urllib.request.urlretrieve 函数下载视频。
defget_video_list(aid,cid,quality):
url_api='https://api.bilibili.com/x/player/playurl?cid={}&bvid={}&qn={}'.format(cid,aid,quality)
headers={
'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/90.0.4430.212Safari/537.36',
'Cookie':'SESSDATA=182cd036%2C1636985829%2C3b393%2A51',
'Host':'api.bilibili.com'
}
html=requests.get(url_api,headers=headers).json()
video_list=[]
foriinhtml['data']['durl']:
video_list.append(i['url'])
returnvideo_list
defschedule_cmd(blocknum,blocksize,totalsize):
percent=100.0*blocknum*blocksize/totalsize
s=('#'*round(percent)).ljust(100,'-')
sys.stdout.write('%.2f%%'%percent+'['+s+']'+'\r')
sys.stdout.flush()
defdownload(video_list,title,bid):
foriinvideo_list:
opener=urllib.request.build_opener()
opener.addheaders=[
('User-Agent','Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/90.0.4430.212Safari/537.36'),
('Accept','*/*'),
('Accept-Language','en-US,en;q=0.5'),
('Accept-Encoding','gzip,deflate,br'),
('Range','bytes=0-'),
('Referer','https://www.bilibili.com/video/'+bid),
('Origin','https://www.bilibili.com'),
('Connection','keep-alive'),
]
filename=os.path.join('D:\\video',r'{}_{}.mp4'.format(bid,title))
try:
urllib.request.install_opener(opener)
urllib.request.urlretrieve(url=i,filename=filename,reporthook=schedule_cmd)
except:
print(bid+"下载异常,文件:"+filename)
到此这篇关于写一个Python脚本下载哔哩哔哩舞蹈区的所有视频的文章就介绍到这了,更多相关python下载哔哩哔哩视频内容请搜索本站以前的文章或继续浏览下面的相关文章希望大家以后多多支持本站!
版权声明:本站文章来源标注为YINGSOO的内容版权均为本站所有,欢迎引用、转载,请保持原文完整并注明来源及原文链接。禁止复制或仿造本网站,禁止在非www.yingsoo.com所属的服务器上建立镜像,否则将依法追究法律责任。本站部分内容来源于网友推荐、互联网收集整理而来,仅供学习参考,不代表本站立场,如有内容涉嫌侵权,请联系alex-e#qq.com处理。
 关注官方微信
关注官方微信