Python正则表达式中的量词符号与组问题小结
发布日期:2022-02-02 16:41 | 文章来源:脚本之家
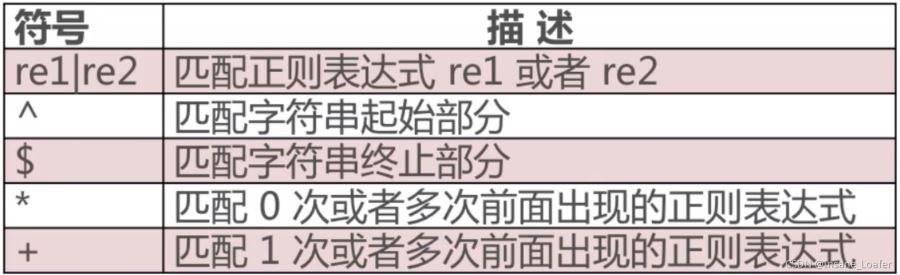
正则表达式中的符号

例子
|是或的关系,只要存在就会被捕获- 匹配到的数据只按字符串顺序返回,而不是按照匹配规则返回
In [18]: data = 'insane@loafer.com'
In [19]: print(re.findall('insane|com|loafer', data))
['insane', 'loafer', 'com']
^ 等同于 \A
In [20]: print(re.findall('^insane',data))
['insane']
In [21]: print(re.findall('^insane1',data))
[]
$ 等同于 \Z
In [22]: print(re.findall('com$',data))
['com']
In [23]: print(re.findall('net$',data))
[]
* 匹配0次或多次
In [24]: print(re.findall('\w*',data))
['insane', '', 'loafer', '', 'com', '']
+匹配1次或多次w+匹配1次或多次数字或字母@和.属于0次范围,不会被匹配出来
In [25]: print(re.findall('\w+',data))
['insane', 'loafer', 'com']
{3} 表示对于匹配到的数据只获取3次
In [31]: data = 'insane@loaf.com'
In [32]: print(re.findall('\w{3}',data))
['ins', 'ane', 'loa', 'com']
In [33]: print(re.findall('[a-z]{3}',data))
['ins', 'ane', 'loa', 'com']
[a-zA-Z0-9]基本上等同于\w
{M, N} 表示对于匹配到的数据只获取M~N次
In [34]: data = 'insane@loaf.com'
In [35]: print(re.findall('\w{1,4}',data))
['insa', 'ne', 'loaf', 'com']
反例:N 和 M 中间不能有空格
In [36]: print(re.findall('\w{1, 4}',data))
[]
[^...] 表示不匹配字符集中的字符
In [37]: data = 'insane@loaf.com'
In [38]: print(re.findall('[^insane]',data))
['@', 'l', 'o', 'f', '.', 'c', 'o', 'm']
组的概念

组的应用
In [42]: test = 'hello my name is insane'
In [43]: result = re.search('hello (.*) name is (.*)', test)
In [44]: result.groups()
Out[44]: ('my', 'insane')
In [45]: result.groups(1)
Out[45]: ('my', 'insane')
In [46]: result.group(1)
Out[46]: 'my'
In [47]: result.group(2)
Out[47]: 'insane'
- 贪婪与非贪婪 0次或多次属于贪婪模式
- 通过
?组合变成非贪婪模式 实战
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2021/8/28 22:13
# @Author: InsaneLoafer
# @File : re_test2.py
import re
def check_url(url):
"""
判断url是否合法
:param url:
:return:
"""
result = re.findall('[a-zA-Z]{4,5}://\w*\.*\w+\.\w+', url)
if len(result) != 0:
return True
else:
return False
def get_url(url):
"""
通过组获取url中的某一部分
:param url:
:return:
"""
result = re.findall('[https://|http://](\w*\.*\w+\.\w+)', url)
if len(result) != 0:
return result[0]
else:
return ''
def get_email(data):
# result = re.findall('[0-9a-zA-Z_]+@[0-9a-zA-Z]+\.[a-zA-Z]+', data)
result = re.findall('.+@.+\.[a-zA-Z]+', data)
return result
html = ('<div class="s-top-nav" style="display:none;">'
'</div><div class="s-center-box"></div>')
def get_html_data(data):
"""
获取style中的display:
使用非贪婪模式
"""
result = re.findall('style="(.*?)"', data)
return result
def get_all_data_html(data):
"""
获取html中所有等号后双引号内的字符
:param data:
:return:
"""
result = re.findall('="(.+?)"', data)
return result
if __name__ == '__main__':
result = check_url('https://www.baidu.com')
print(result)
result = get_url('https://www.baidu.com')
print(result, 'https')
result = get_url('http://www.baidu.com')
print(result, 'http')
result = get_email('insane@163.net')
print(result)
result = get_html_data(html)
print(result)
result = get_all_data_html(html)
print(result)
True www.baidu.com https www.baidu.com http ['insane@163.net'] ['display:none;'] ['s-top-nav', 'display:none;', 's-center-box'] Process finished with exit code 0
到此这篇关于Python正则表达式中的量词符号与组的文章就介绍到这了,更多相关python正则表达式量词内容请搜索本站以前的文章或继续浏览下面的相关文章希望大家以后多多支持本站!
版权声明:本站文章来源标注为YINGSOO的内容版权均为本站所有,欢迎引用、转载,请保持原文完整并注明来源及原文链接。禁止复制或仿造本网站,禁止在非www.yingsoo.com所属的服务器上建立镜像,否则将依法追究法律责任。本站部分内容来源于网友推荐、互联网收集整理而来,仅供学习参考,不代表本站立场,如有内容涉嫌侵权,请联系alex-e#qq.com处理。
相关文章
 关注官方微信
关注官方微信