Pandas使用stack和pivot实现数据透视的方法
笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章。本节主要记录Pandas中使用stack和pivot实现数据透视。
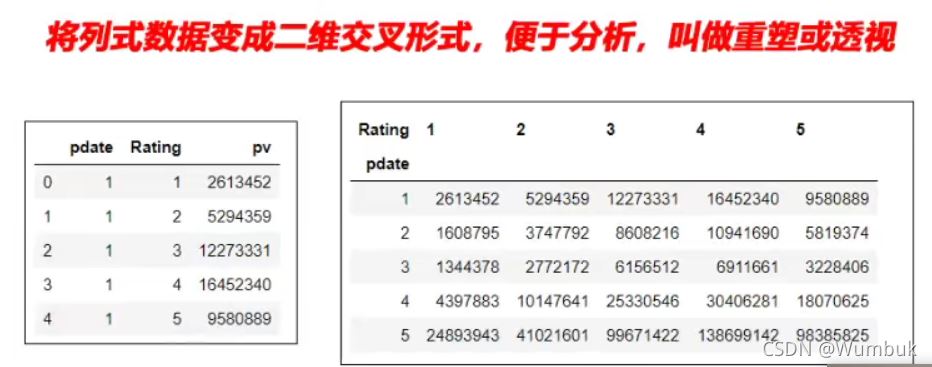
一、经过统计得到多维度指标数据
非常场景的统计场景,指定多个维度,计算聚合后的指标
实例:统计得到“电影评分数据集”,每个月份的每个分数被评分多少次:(月份、分数1-5、次数)
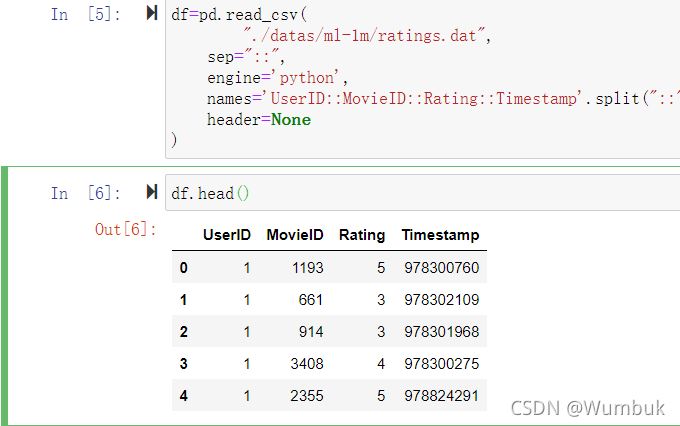
import pandas as pd
import numpy as np
%matplotlib inline
df=pd.read_csv(
"./datas/ml-1m/ratings.dat",
sep="::",
engine='python',
names='UserID::MovieID::Rating::Timestamp'.split("::"),
header=None
)
df.head()
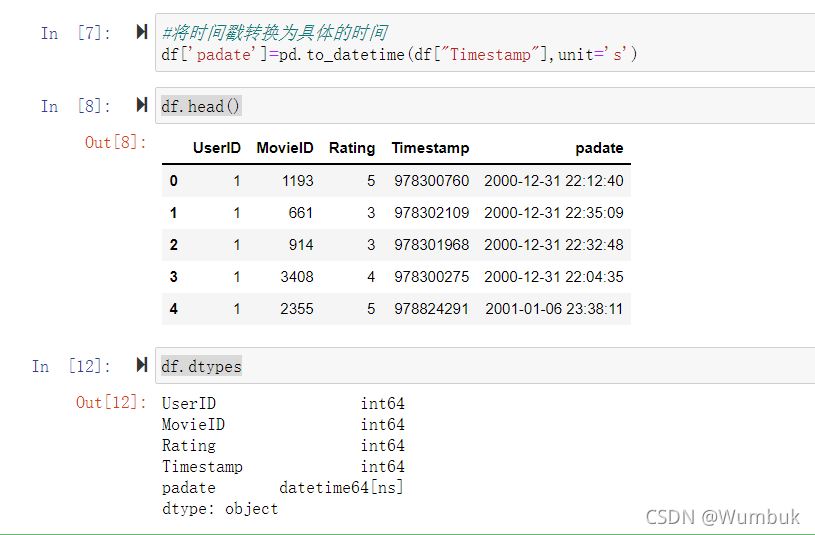
#将时间戳转换为具体的时间
df['padate']=pd.to_datetime(df["Timestamp"],unit='s')
df.head()
df.dtypes
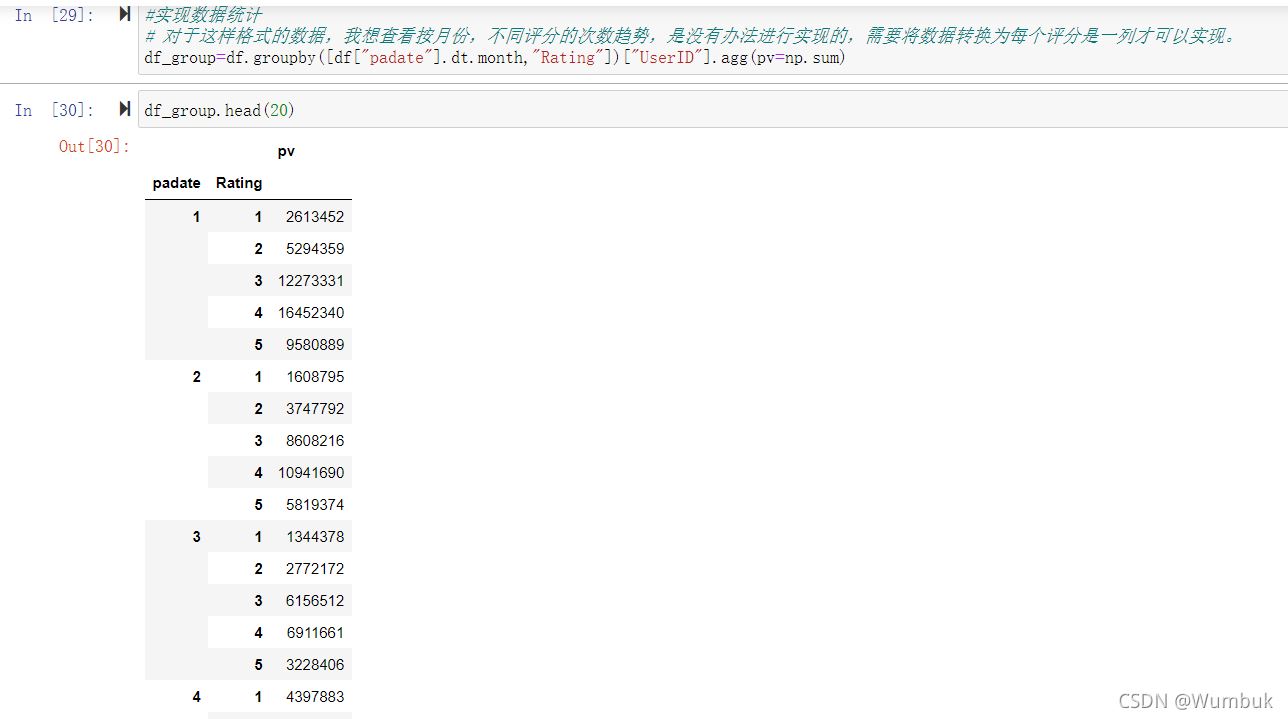
#实现数据统计
# 对于这样格式的数据,我想查看按月份,不同评分的次数趋势,是没有办法进行实现的,需要将数据转换为每个评分是一列才可以实现。
df_group=df.groupby([df["padate"].dt.month,"Rating"])["UserID"].agg(pv=np.sum)
df_group.head(20)
二、使用unstack实现数据的二维透视
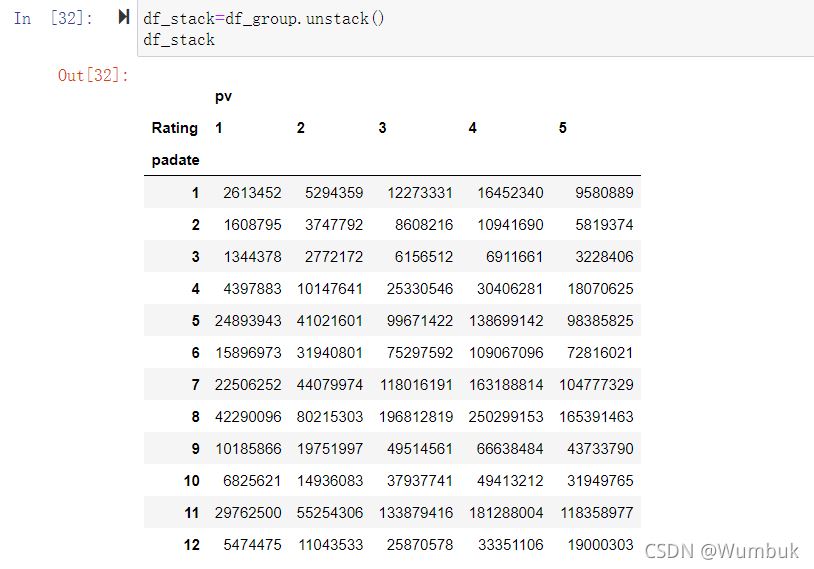
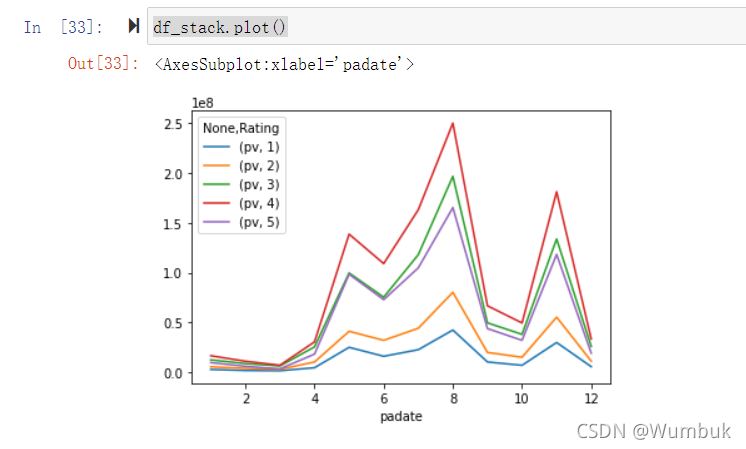
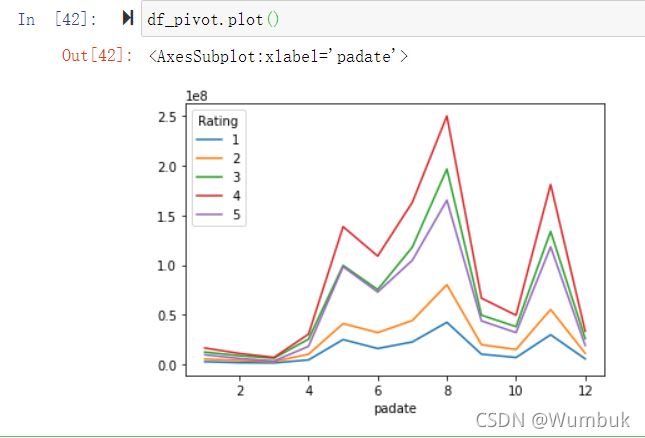
目的: 想要画图对比按照月份的不同评分的数量趋势
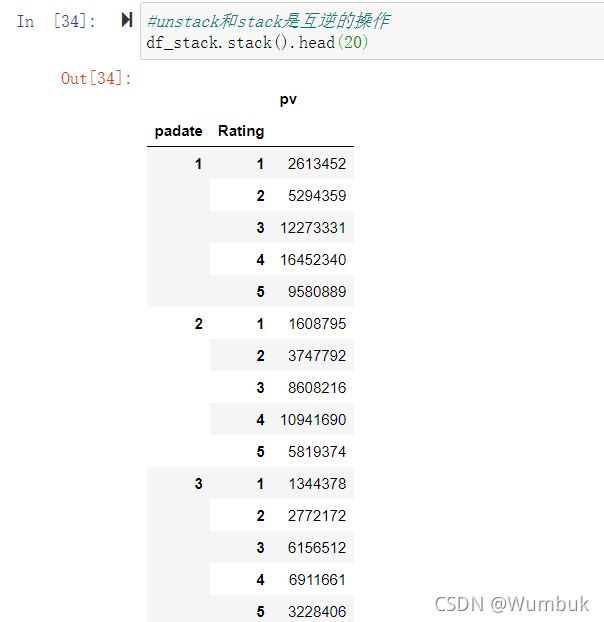
df_stack=df_group.unstack() df_stack df_stack.plot() #unstack和stack是互逆的操作 df_stack.stack().head(20)
三、使用pivot简化透视
pivot方法相当于对df使用set_index创建分层索引,然后调用unstack
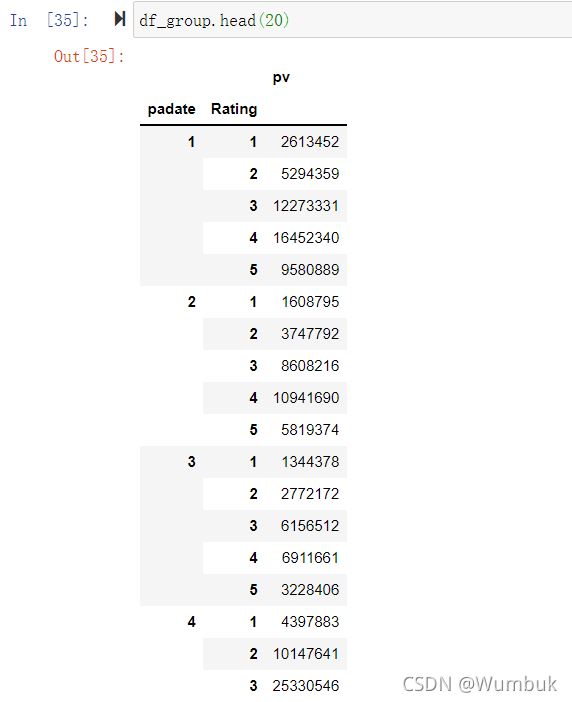
df_group.head(20)
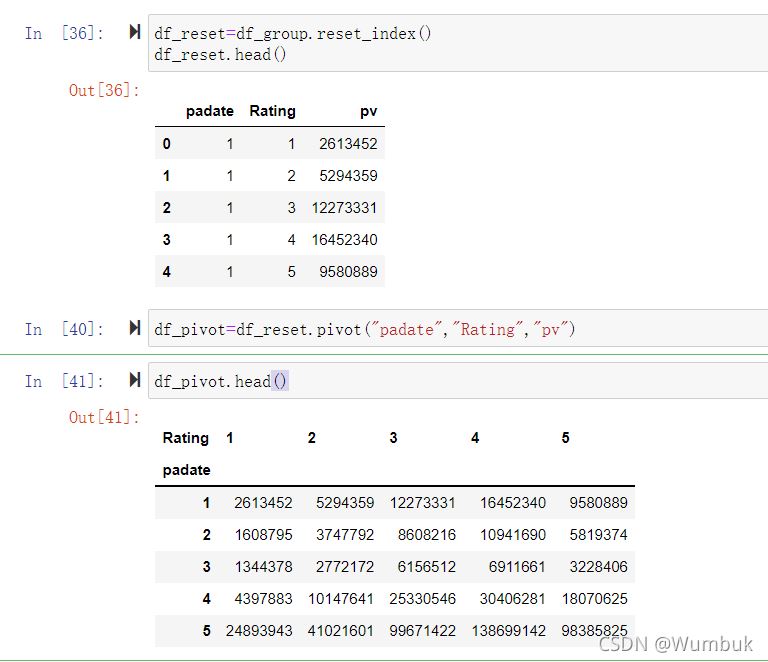
df_reset=df_group.reset_index()
df_reset.head()
df_pivot=df_reset.pivot("padate","Rating","pv")
df_pivot.head()
df_pivot.plot()
四、stack、unstack、pivot的语法
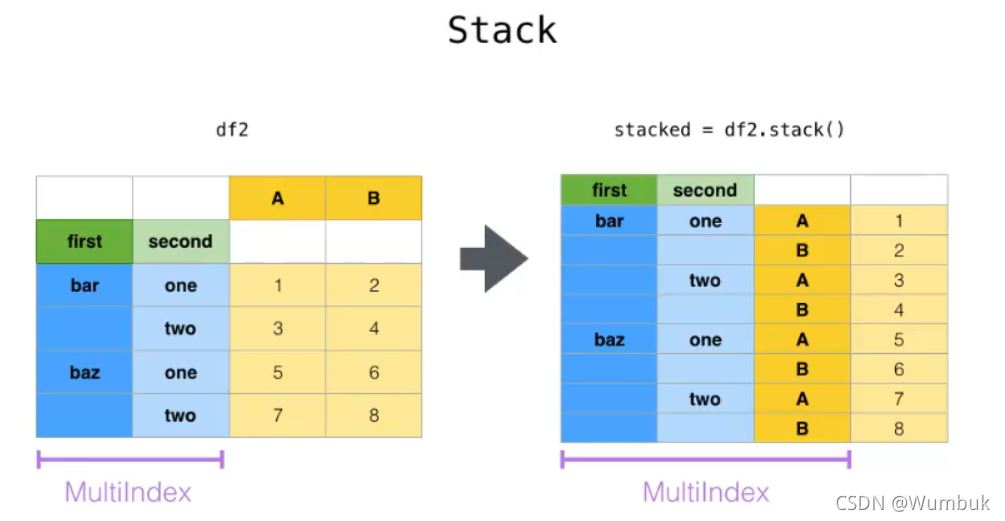
1.stack
stack:DataFrame.stack(level=-1,dropna=True),将column变成index,类似把横放的书籍变成竖放
level=-1代表多层索引的最内层,可以通过==0,1,2指定多层索引的对应层
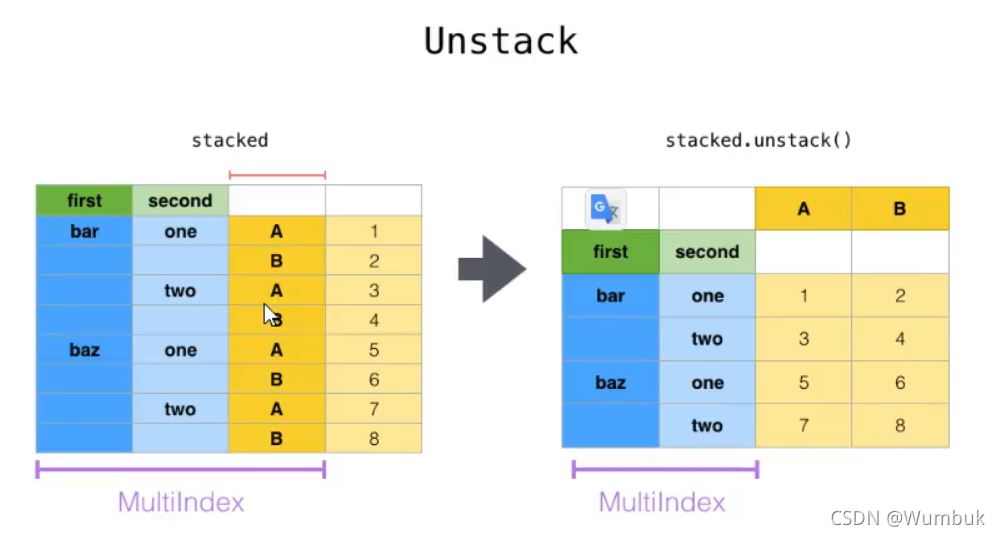
2.unstack
unstack:DataFrame.unstack(level=-1,fill_value=None),将index变成column,类似把竖放的书变成横放
3.pivot
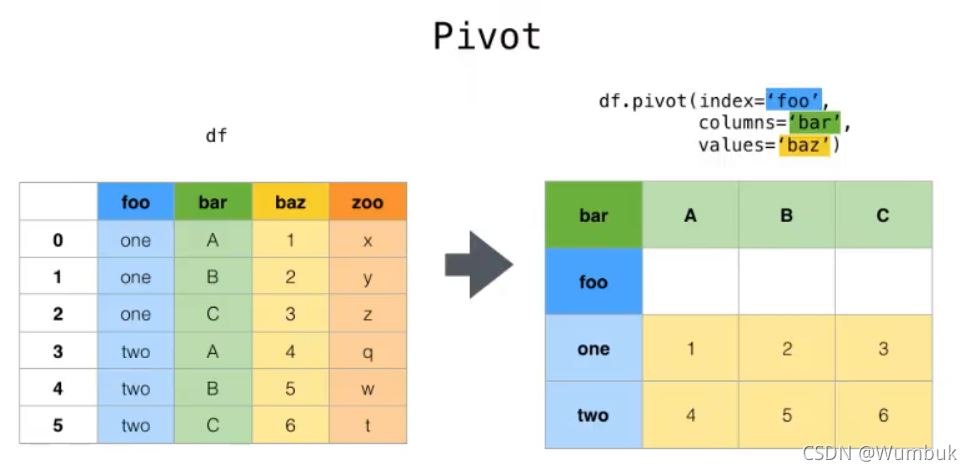
pivot:DataFrame.pivot(index=None,columns=None,values=None),指定index,columns,values实现二维透视
总结
到此这篇关于Pandas使用stack和pivot实现数据透视的方法的文章就介绍到这了,更多相关Pandas stack和pivot数据透视内容请搜索本站以前的文章或继续浏览下面的相关文章希望大家以后多多支持本站!
版权声明:本站文章来源标注为YINGSOO的内容版权均为本站所有,欢迎引用、转载,请保持原文完整并注明来源及原文链接。禁止复制或仿造本网站,禁止在非www.yingsoo.com所属的服务器上建立镜像,否则将依法追究法律责任。本站部分内容来源于网友推荐、互联网收集整理而来,仅供学习参考,不代表本站立场,如有内容涉嫌侵权,请联系alex-e#qq.com处理。
 关注官方微信
关注官方微信