Python实现数据透视表详解
发布日期:2021-12-18 04:38 | 文章来源:站长之家
用Python里的Pandas可以实现,虽然感觉Excel更方便
1.groupby + agg
不够直观,不好看
对贷款年份,贷款种类创建数据透视
train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean'))
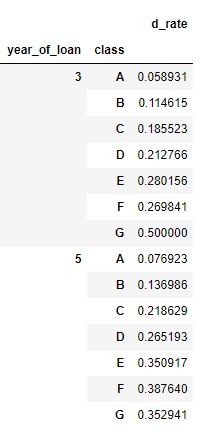
2. crosstab
pandas.crosstab(index, columns,values, rownames=None, colnames, aggfunc, margins, margins_name, dropna, normalize)
主要用到的参数:
index:选哪个变量做数据透视表的行
columns:选哪个变量做数据透视表的列
values:要聚合的值
aggfunc:使用的聚合函数
margins:是否添加汇总列/行
margins_name:汇总行/列的名字
例子
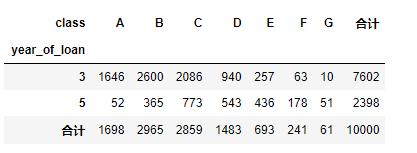
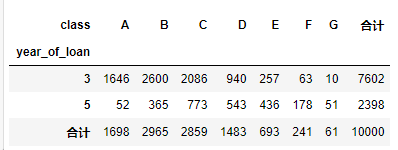
对贷款年份,贷款种类创建数据透视
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['loan_id'], aggfunc='count',margins = True, margins_name = '合计')
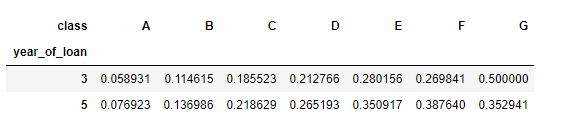
可以直接看出交叉组合之后违约比例
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['isDefault'], aggfunc='mean')
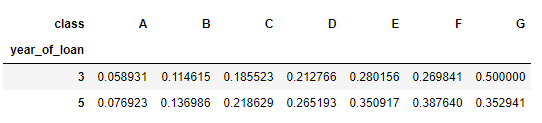
3.groupby + pivot
train_data.groupby(['year_of_loan', 'class'], as_index = False)['isDefault'].mean().pivot('year_of_loan', 'class', 'isDefault')
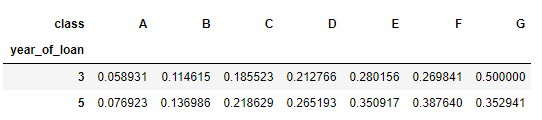
pivot_table
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
常用参数与crosstab一致
例子
实现同样的数据透视表
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
pd.pivot_table(train_data[['year_of_loan', 'class', 'isDefault']], values='isDefault', index=['year_of_loan'], columns=['class'], aggfunc='mean')
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注本站的更多内容!
版权声明:本站文章来源标注为YINGSOO的内容版权均为本站所有,欢迎引用、转载,请保持原文完整并注明来源及原文链接。禁止复制或仿造本网站,禁止在非www.yingsoo.com所属的服务器上建立镜像,否则将依法追究法律责任。本站部分内容来源于网友推荐、互联网收集整理而来,仅供学习参考,不代表本站立场,如有内容涉嫌侵权,请联系alex-e#qq.com处理。
相关文章
 关注官方微信
关注官方微信