Python通过requests模块实现抓取王者荣耀全套皮肤
今天带大家爬取王者荣耀全套皮肤,废话不多说,直接开始~
开发工具
Python版本: 3.6.4
相关模块:
requests模块;
urllib模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
思路分析
1、打开官方王者荣耀壁纸网站
网站地址:https://pvp.qq.com/web201605/wallpaper.shtml
2、快捷键F12,调出控制台进行抓包
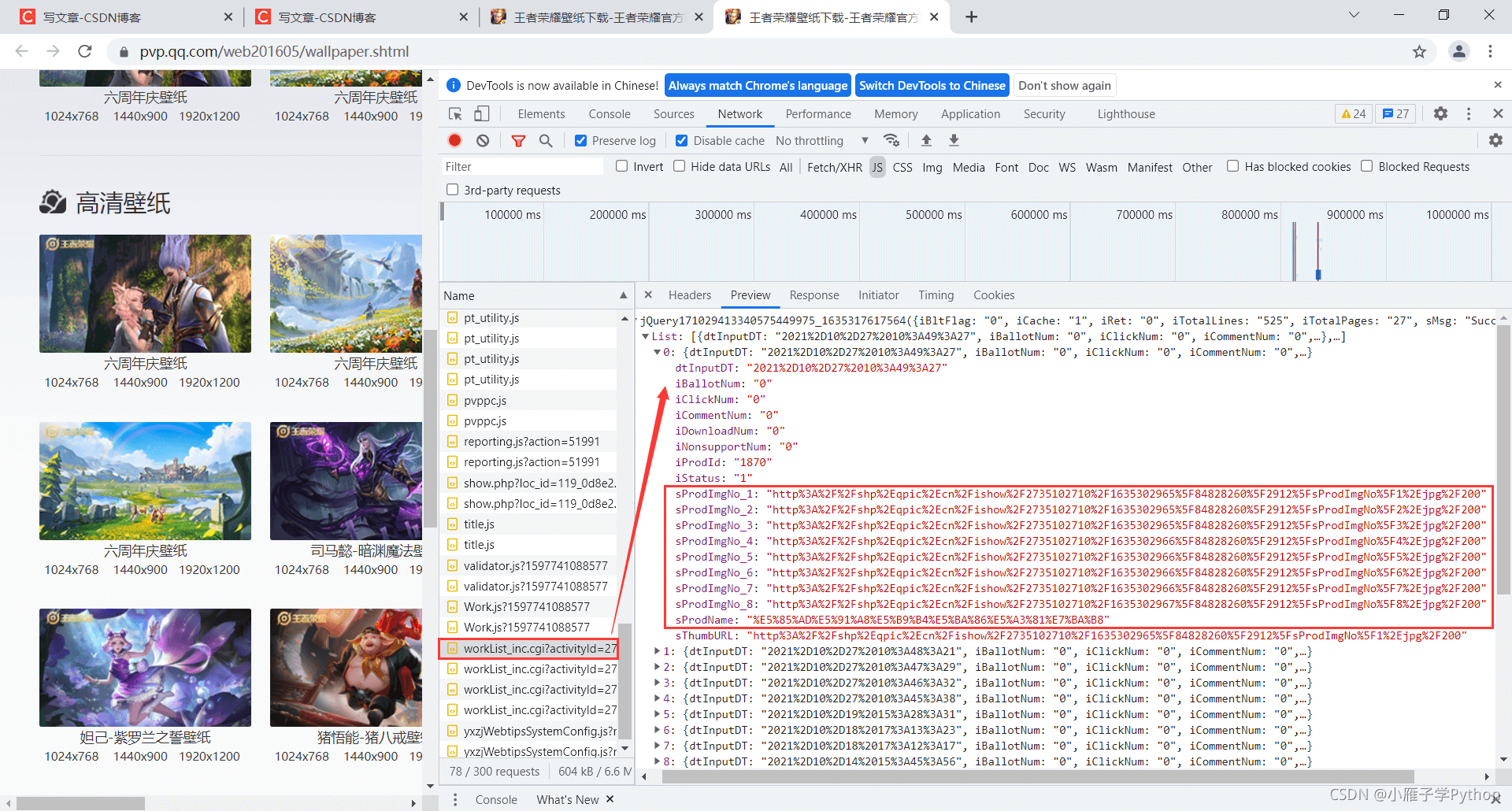
3、找到正确的链接并分析
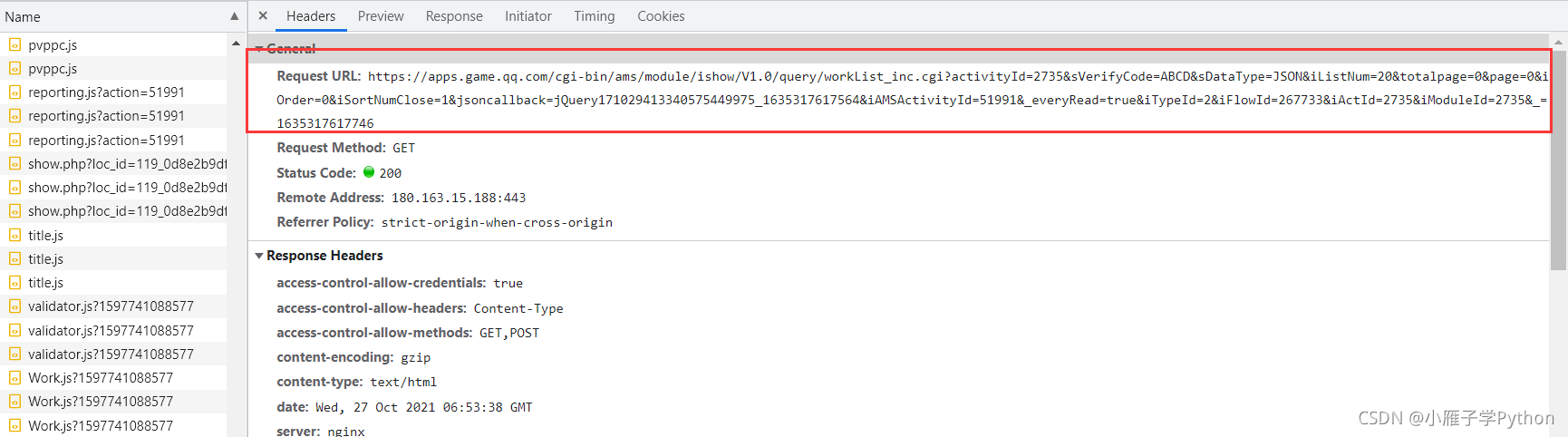
4、查看返回数据格式
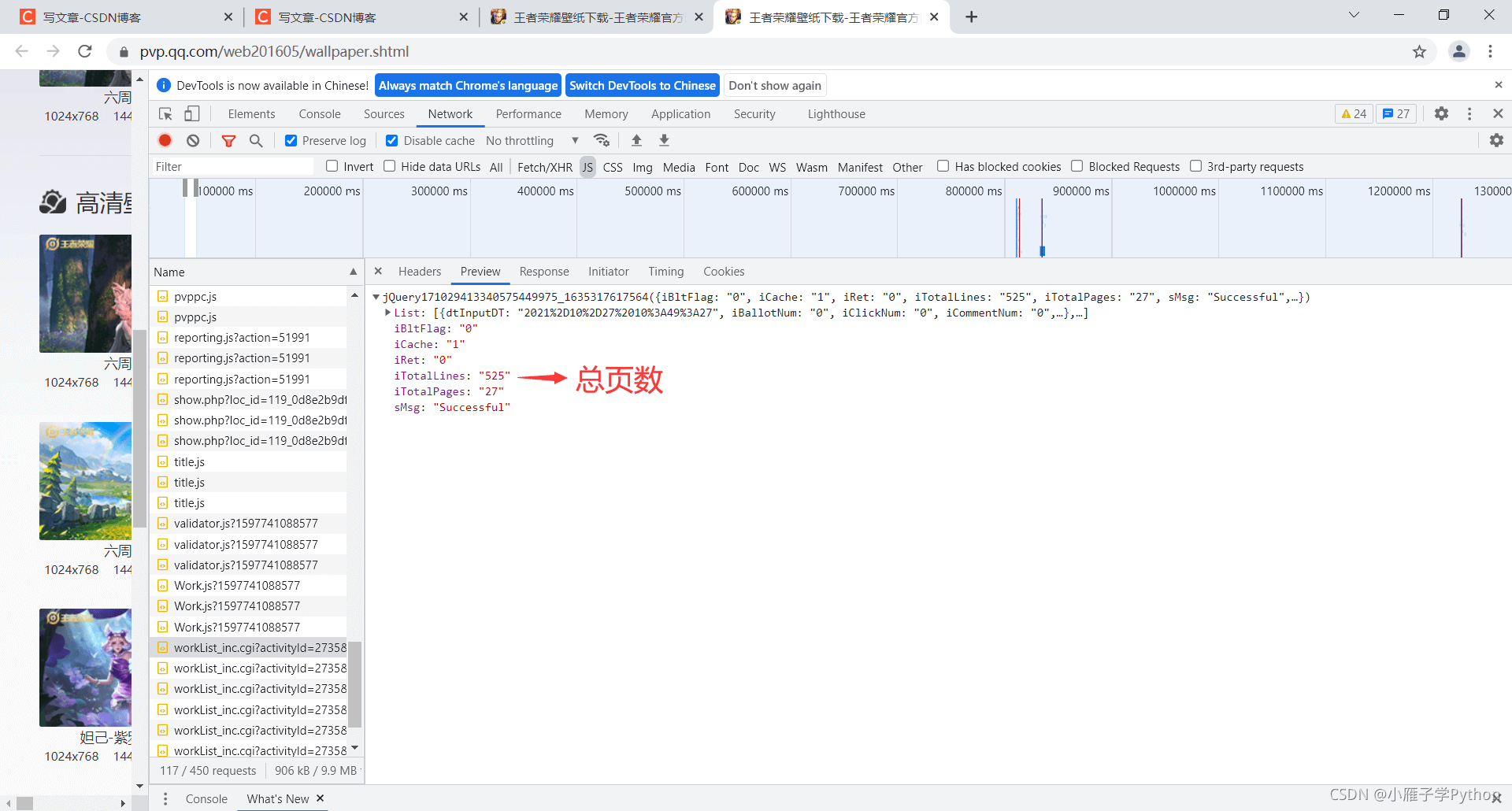
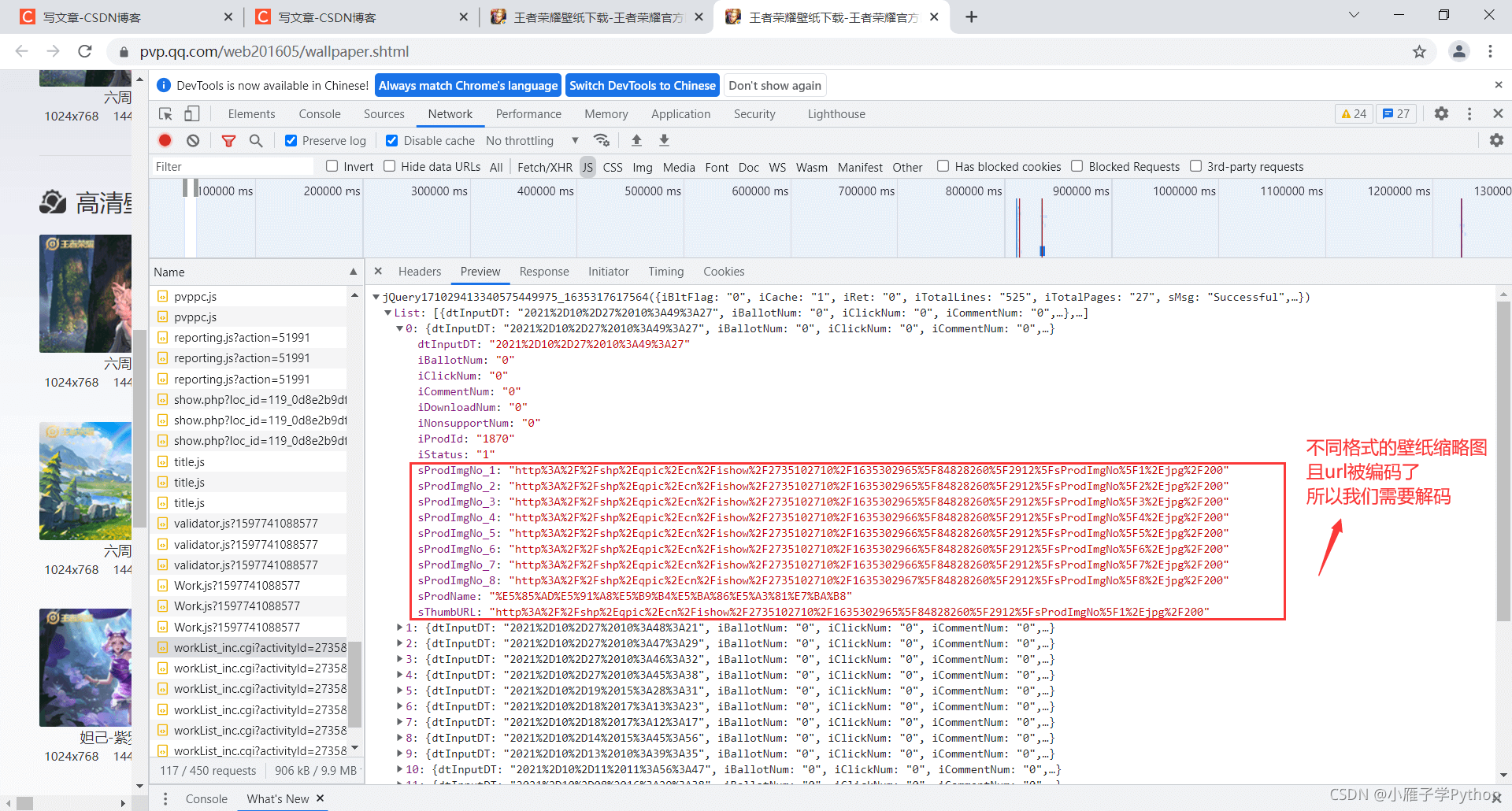
5、解析url链接
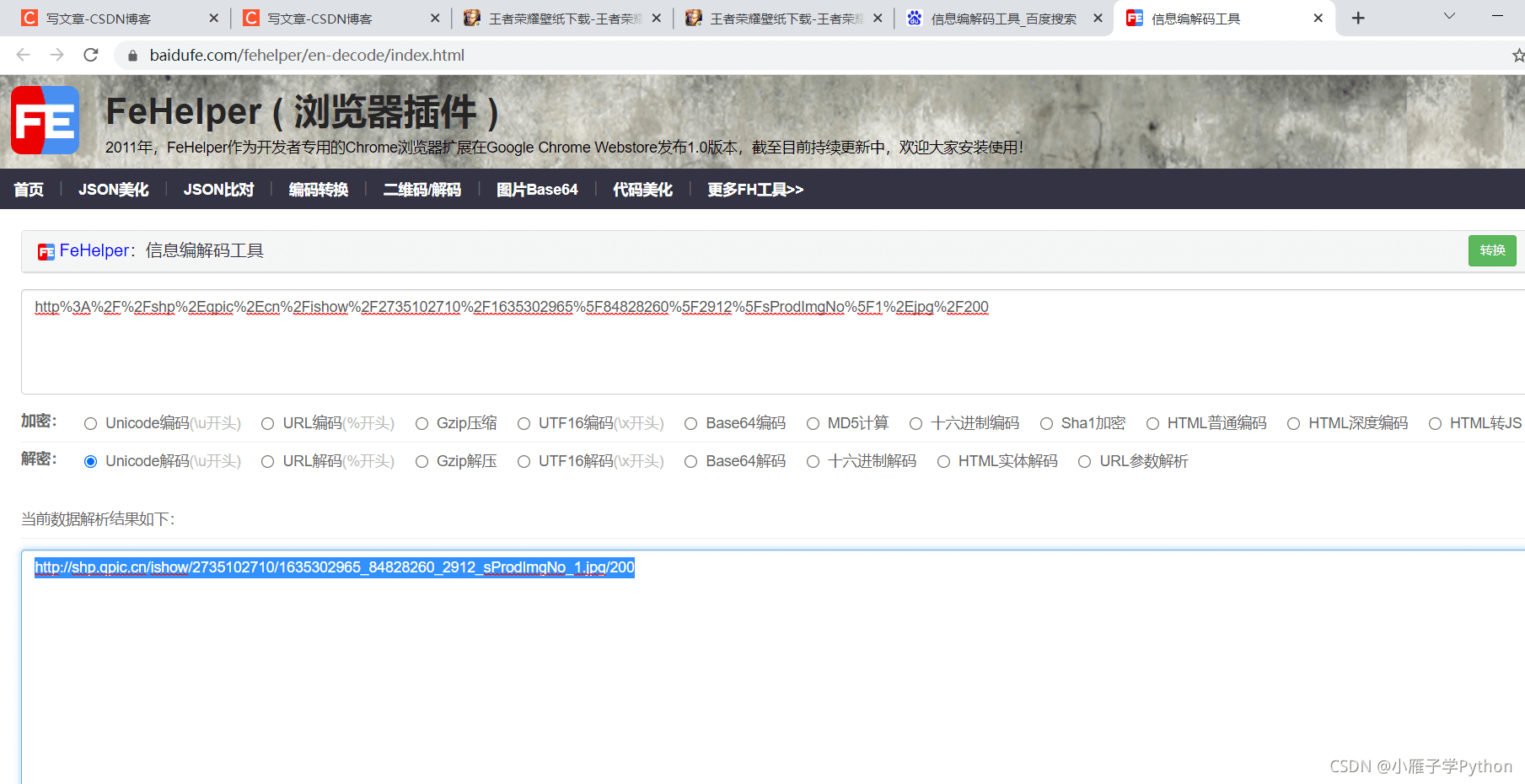
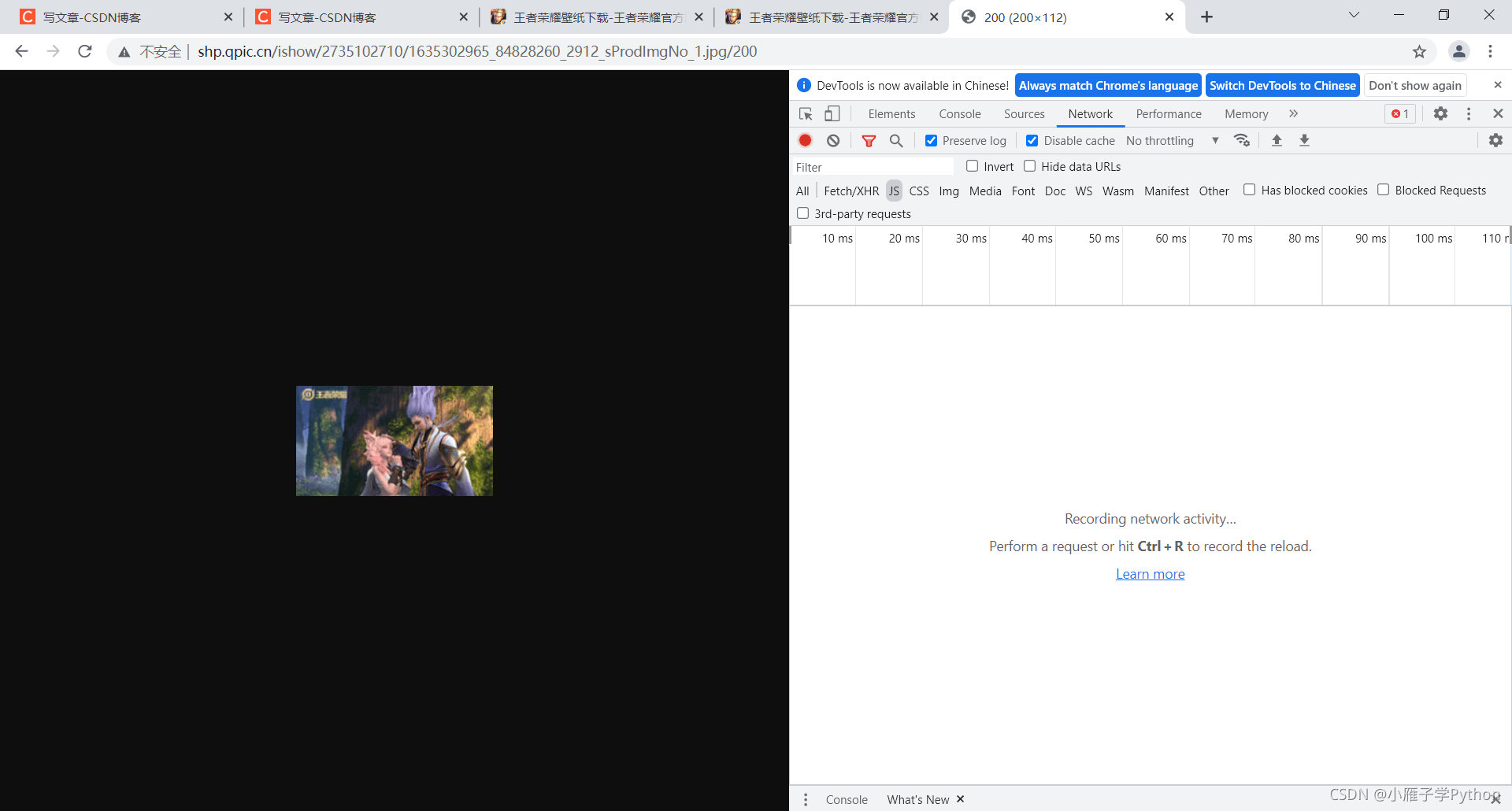
6、查看url内容是否是所需图片,发现其实是缩略图
7、那就去分析网站,随便点开一张壁纸,查看指定格式的链接
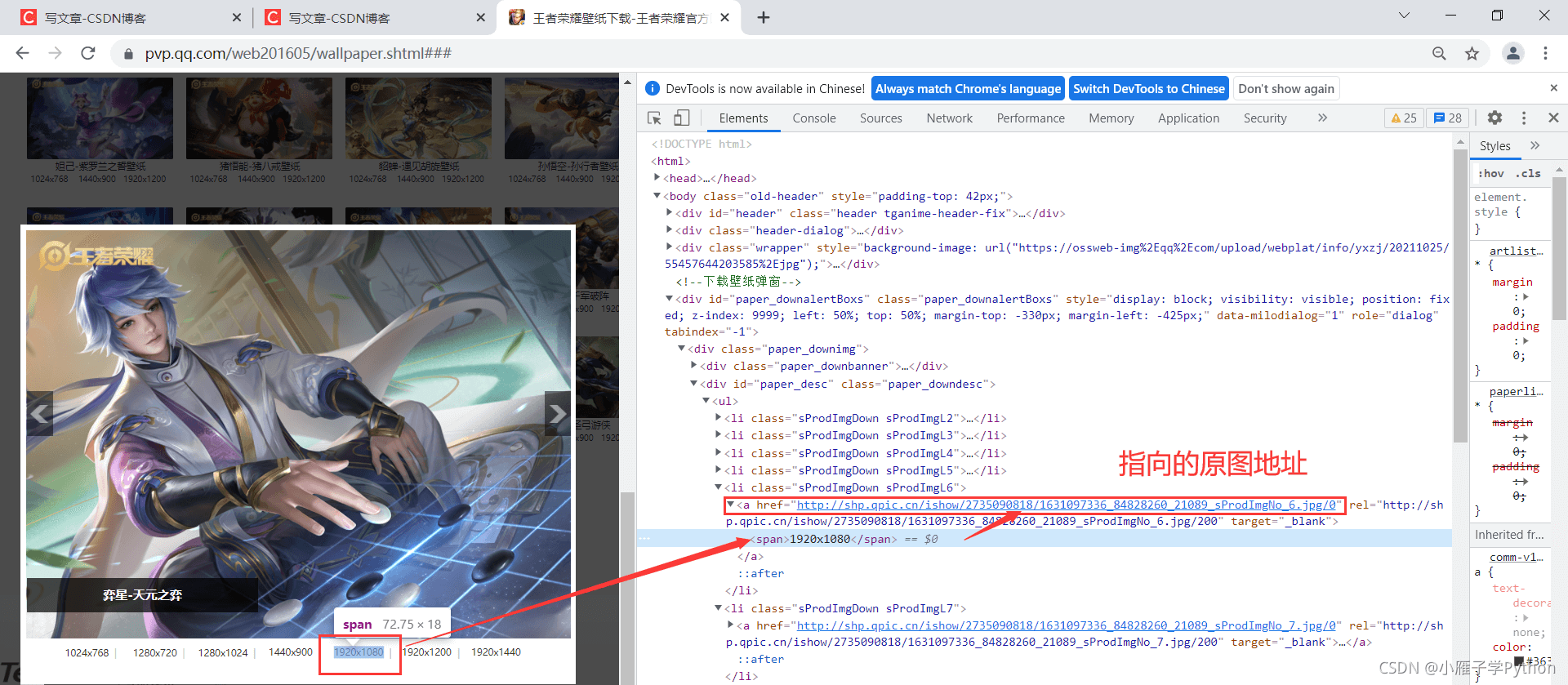
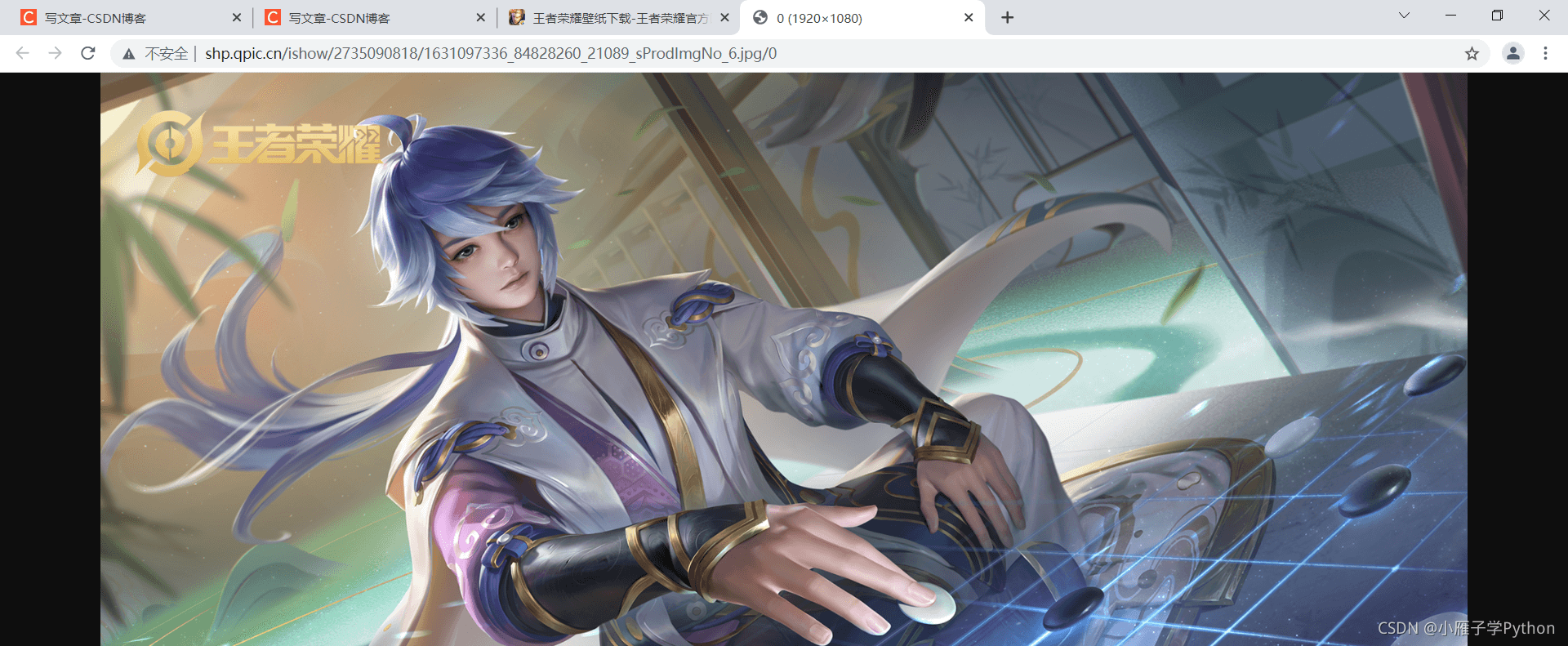
8、找到目标地址
9、分析目标链接和缩略图的链接区别
缩略图:http://shp.qpic.cn/ishow/2735090714/1599460171_84828260_8311_sProdImgNo_6.jpg/200
目标图:http://shp.qpic.cn/ishow/2735090714/1599460171_84828260_8311_sProdImgNo_6.jpg/0
可以知道,将指定格式的缩略图地址后面200替换成0就是目标真实图片
代码实现
import os, time, requests, json, re
from retrying import retry
from urllib import parse
class HonorOfKings:
'''
This is a main Class, the file contains all documents.
One document contains paragraphs that have several sentences
It loads the original file and converts the original file to new content
Then the new content will be saved by this class
'''
def __init__(self, save_path='./heros'):
self.save_path = save_path
self.time = str(time.time()).split('.')
self.url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=%s' % self.time[0]
def hello(self):
'''
This is a welcome speech
:return: self
'''
print("*" * 50)
print(' ' * 18 + '王者荣耀壁纸下载')
print(' ' * 5 + '作者: Felix Date: 2020-05-20 13:14')
print("*" * 50)
return self
def run(self):
'''
The program entry
'''
print('↓' * 20 + ' 格式选择: ' + '↓' * 20)
print('1.缩略图 2.1024x768 3.1280x720 4.1280x1024 5.1440x900 6.1920x1080 7.1920x1200 8.1920x1440')
size = input('请输入您想下载的格式序号,默认6:')
size = size if size and int(size) in [1,2,3,4,5,6,7,8] else 6
print('---下载开始...')
page = 0
offset = 0
total_response = self.request(self.url.format(page)).text
total_res = json.loads(total_response)
total_page = --int(total_res['iTotalPages'])
print('---总共 {} 页...' . format(total_page))
while True:
if offset > total_page:
break
url = self.url.format(offset)
response = self.request(url).text
result = json.loads(response)
now = 0
for item in result["List"]:
now += 1
hero_name = parse.unquote(item['sProdName']).split('-')[0]
hero_name = re.sub(r'[【】:.<>|·@#$%^&() ]', '', hero_name)
print('---正在下载第 {} 页 {} 英雄 进度{}/{}...' . format(offset, hero_name, now, len(result["List"])))
hero_url = parse.unquote(item['sProdImgNo_{}'.format(str(size))])
save_path = self.save_path + '/' + hero_name
save_name = save_path + '/' + hero_url.split('/')[-2]
if not os.path.exists(save_path):
os.makedirs(save_path)
if not os.path.exists(save_name):
with open(save_name, 'wb') as f:response_content = self.request(hero_url.replace("/200", "/0")).contentf.write(response_content)
offset += 1
print('---下载完成...')
@retry(stop_max_attempt_number=3)
def request(self, url):
'''
Send a request
:param url: the url of request
:param timeout: the time of request
:return: the result of request
'''
response = requests.get(url, timeout=10)
assert response.status_code == 200
return response
if __name__ == "__main__":
HonorOfKings().hello().run()
本期完整源代码可以私信获取
代码运行结果
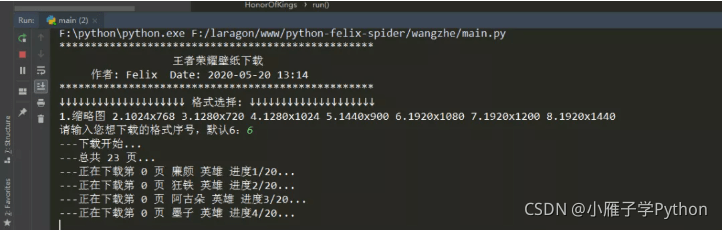
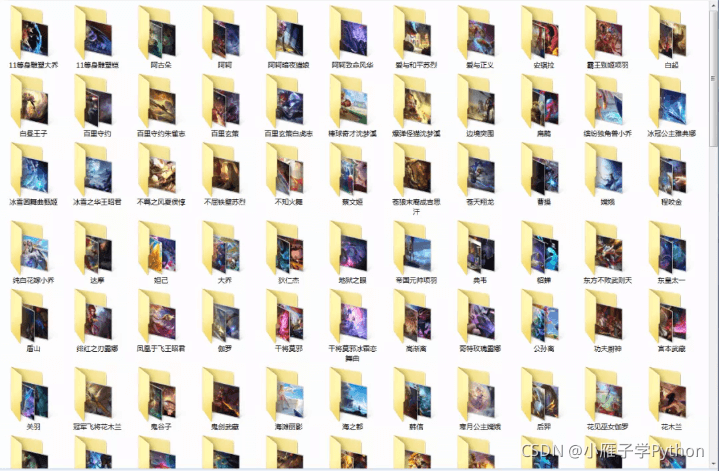
到此这篇关于Python通过requests模块实现抓取王者荣耀全套皮肤的文章就介绍到这了,更多相关Python 抓取王者荣耀皮肤内容请搜索本站以前的文章或继续浏览下面的相关文章希望大家以后多多支持本站!
版权声明:本站文章来源标注为YINGSOO的内容版权均为本站所有,欢迎引用、转载,请保持原文完整并注明来源及原文链接。禁止复制或仿造本网站,禁止在非www.yingsoo.com所属的服务器上建立镜像,否则将依法追究法律责任。本站部分内容来源于网友推荐、互联网收集整理而来,仅供学习参考,不代表本站立场,如有内容涉嫌侵权,请联系alex-e#qq.com处理。
 关注官方微信
关注官方微信