Python Pandas两个表格内容模糊匹配的实现
发布日期:2021-12-12 00:12 | 文章来源:CSDN
一、方法2
此方法是两个表构建某一相同字段,然后全连接,在做匹配结果筛选,此方法针对数据量不大的时候,逻辑比较简单,但是内存消耗较大
1. 导入库
import pandas as pd import numpy as np import re
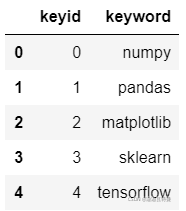
2. 构建关键词
#关键词数据
df_keyword = pd.DataFrame({
"keyid" : np.arange(5),
"keyword" : ["numpy", "pandas", "matplotlib", "sklearn", "tensorflow"]
})
df_keyword
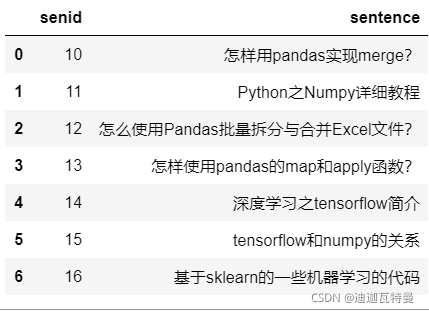
3. 构建句子
df_sentence = pd.DataFrame({
"senid" : np.arange(10,17),
"sentence" : [
"怎样用pandas实现merge?",
"Python之Numpy详细教程",
"怎么使用Pandas批量拆分与合并Excel文件?",
"怎样使用pandas的map和apply函数?",
"深度学习之tensorflow简介",
"tensorflow和numpy的关系",
"基于sklearn的一些机器学习的代码"
]
})
df_sentence
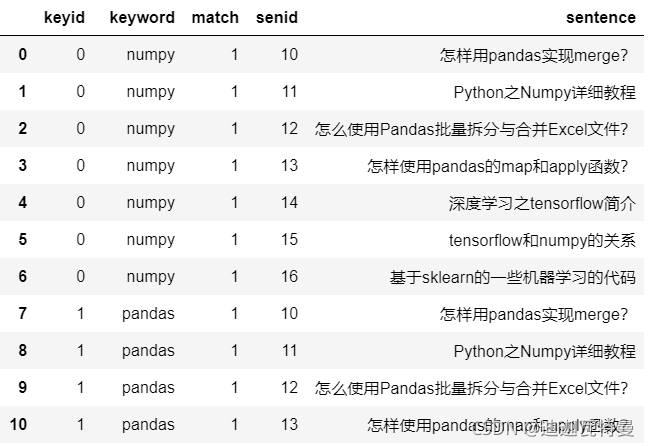
4. 建立统一索引
df_keyword['match'] = 1 df_sentence['match'] = 1
5. 表连接
df_merge = pd.merge(df_keyword, df_sentence) df_merge
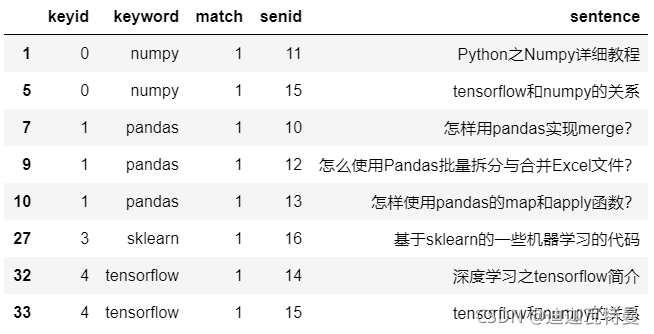
6. 关键词匹配
def match_func(row): return re.search(row["keyword"], row["sentence"], re.IGNORECASE) is not None df_merge[df_merge.apply(match_func, axis = 1)]
匹配结果如下
二、方法2
此方法对编程能力有要求,在大数据集上计算量较方法一小很多
1. 构建字典
key_word_dict = {
row.keyword : row.keyid
for row in df_keyword.itertuples()
}
key_word_dict
{'numpy': 0, 'pandas': 1, 'matplotlib': 2, 'sklearn': 3, 'tensorflow': 4}
2. 关键词匹配
def merge_func(row): #新增一列,表示可以匹配的keyid row["keyids"] = [ keyid for key_word, keyid in key_word_dict.items() if re.search(key_word, row["sentence"], re.IGNORECASE) ] return row df_merge = df_sentence.apply(merge_func, axis = 1)
3. 结果展示
df_merge
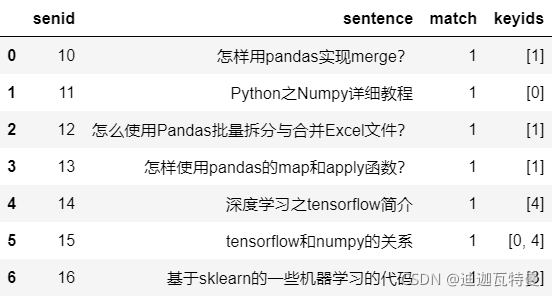
4. 匹配结果展开
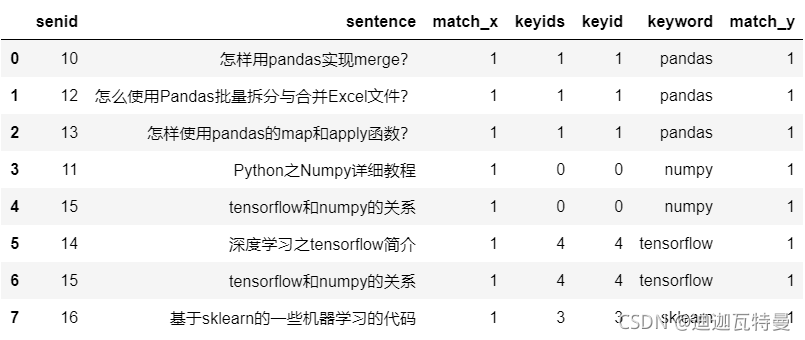
df_result = pd.merge(
left = df_merge.explode("keyids"),
right = df_keyword,
left_on = "keyids",
right_on = "keyid")
df_result
总结
到此这篇关于Python Pandas两个表格内容模糊匹配搜索本站以前的文章或继续浏览下面的相关文章希望大家以后多多支持本站!
版权声明:本站文章来源标注为YINGSOO的内容版权均为本站所有,欢迎引用、转载,请保持原文完整并注明来源及原文链接。禁止复制或仿造本网站,禁止在非www.yingsoo.com所属的服务器上建立镜像,否则将依法追究法律责任。本站部分内容来源于网友推荐、互联网收集整理而来,仅供学习参考,不代表本站立场,如有内容涉嫌侵权,请联系alex-e#qq.com处理。
相关文章
 关注官方微信
关注官方微信